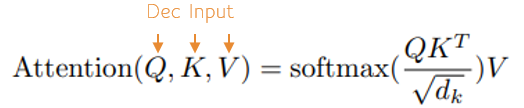Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
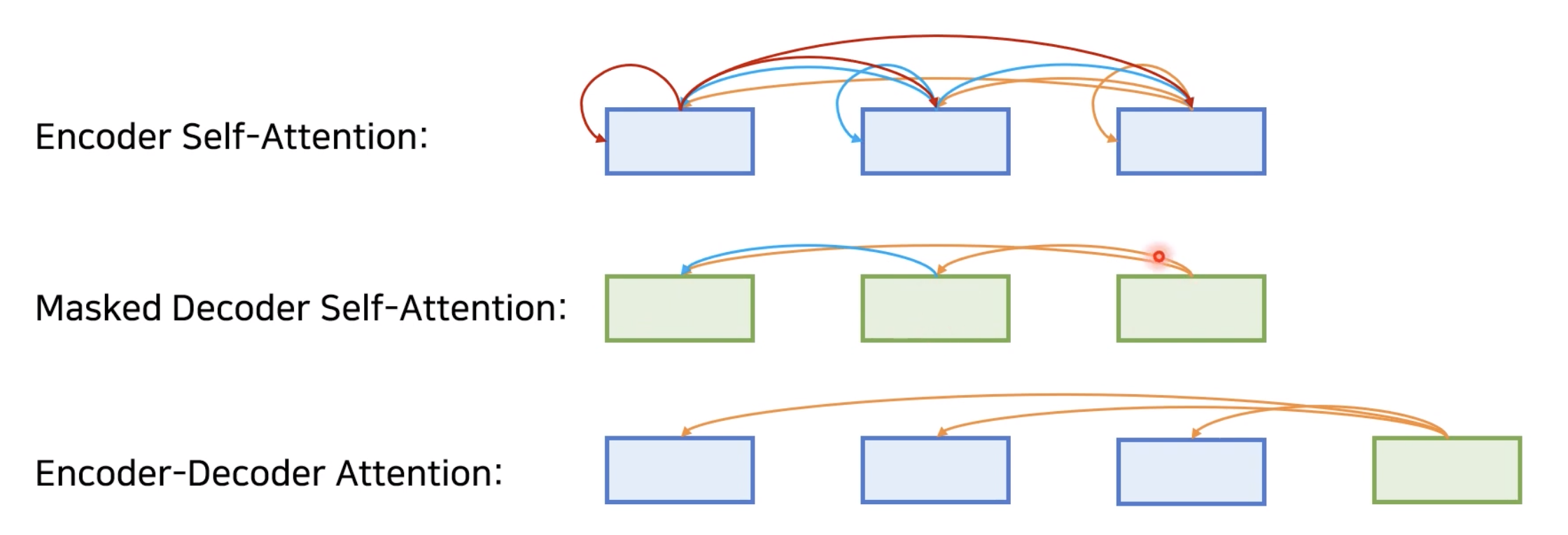
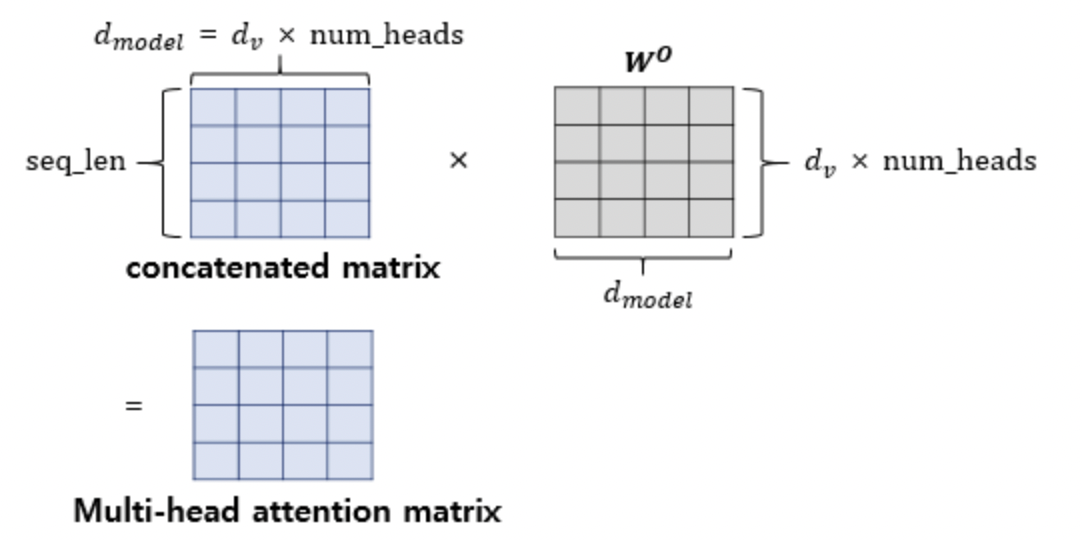
Transformer 논문 리뷰 전 프리뷰1(Attention의 흐름과 Self Attention, Masked Decoder ...
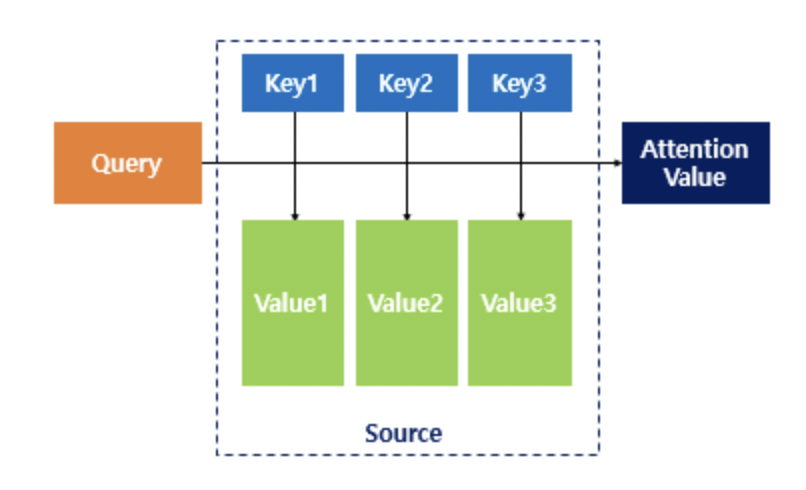
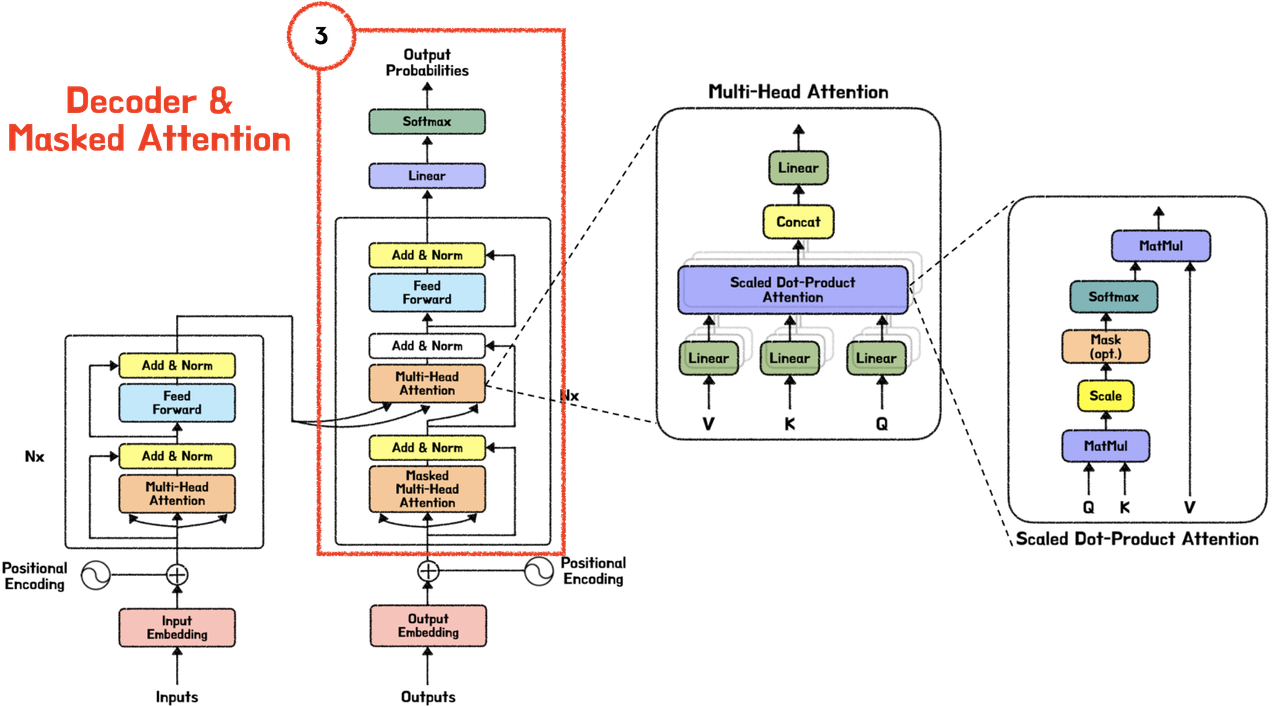
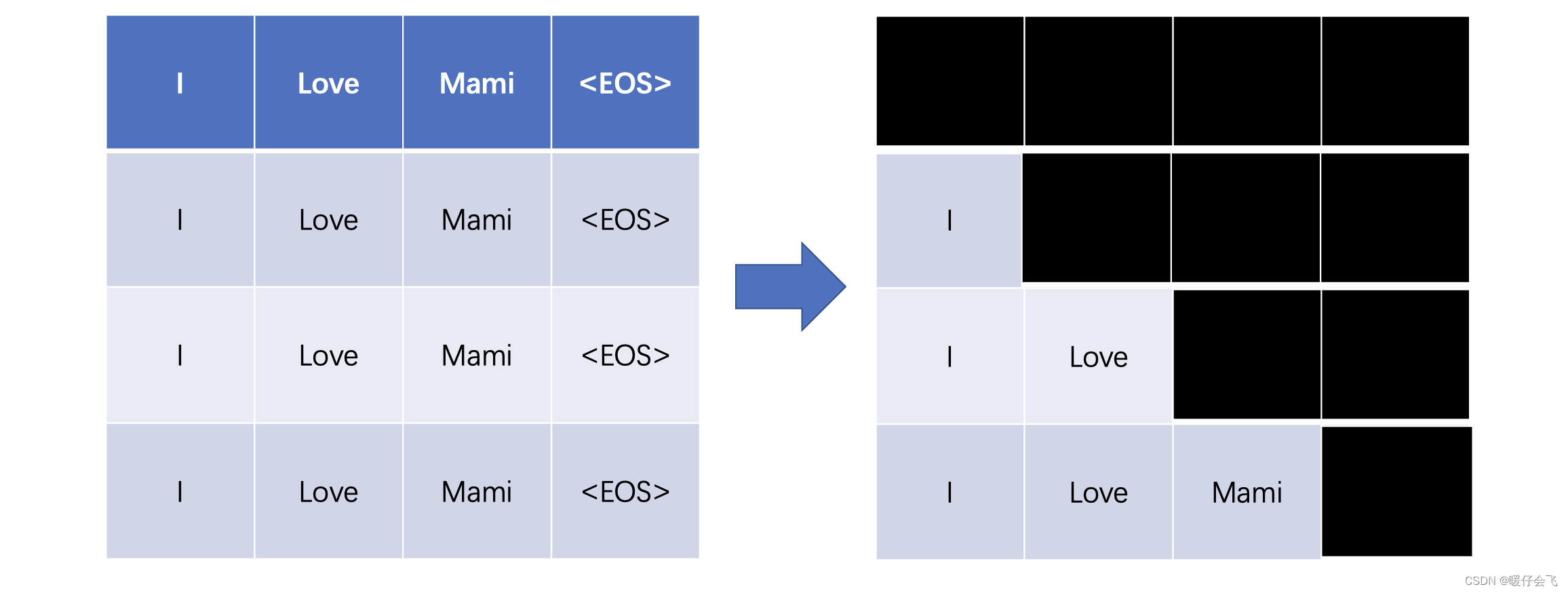
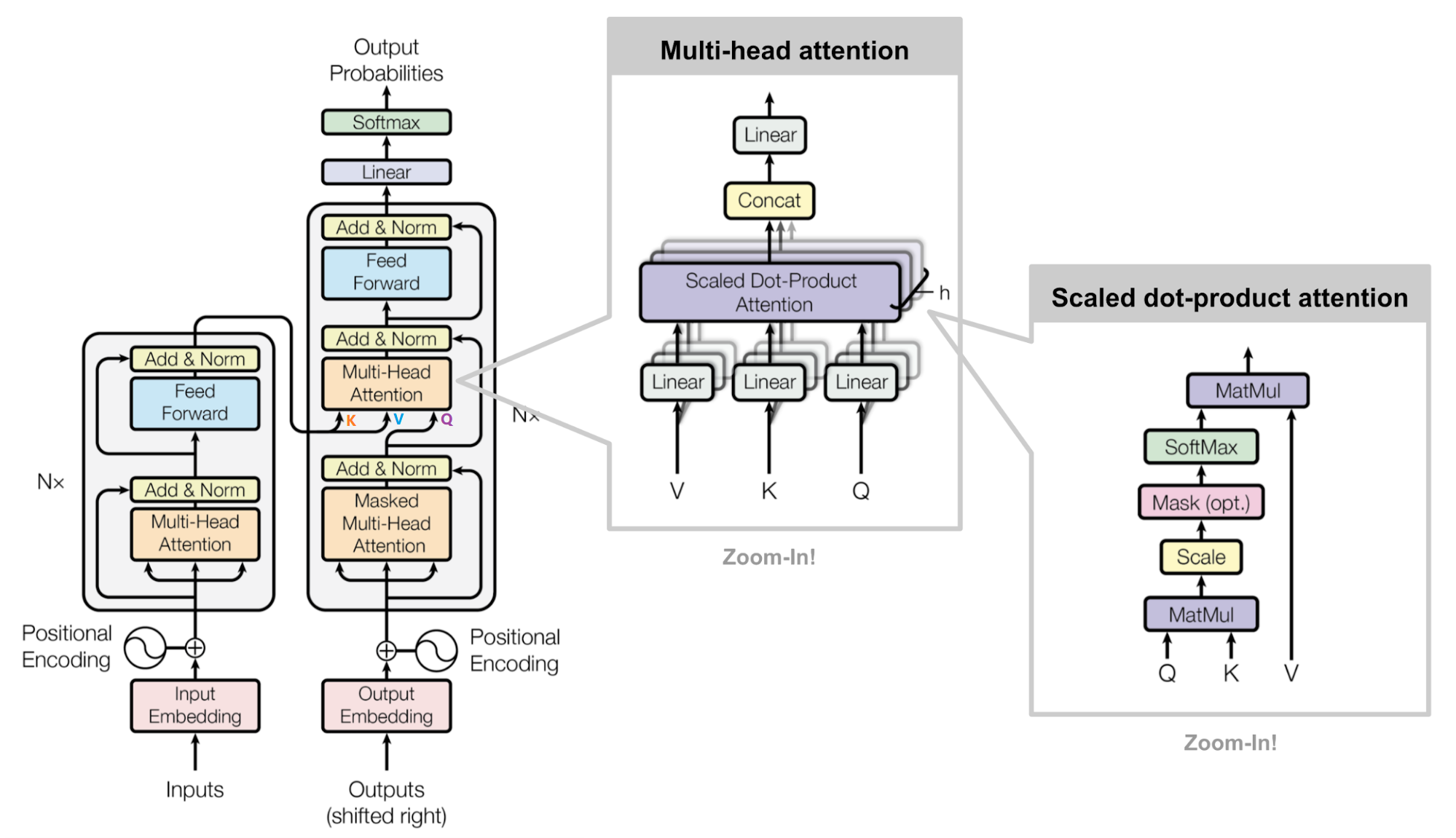
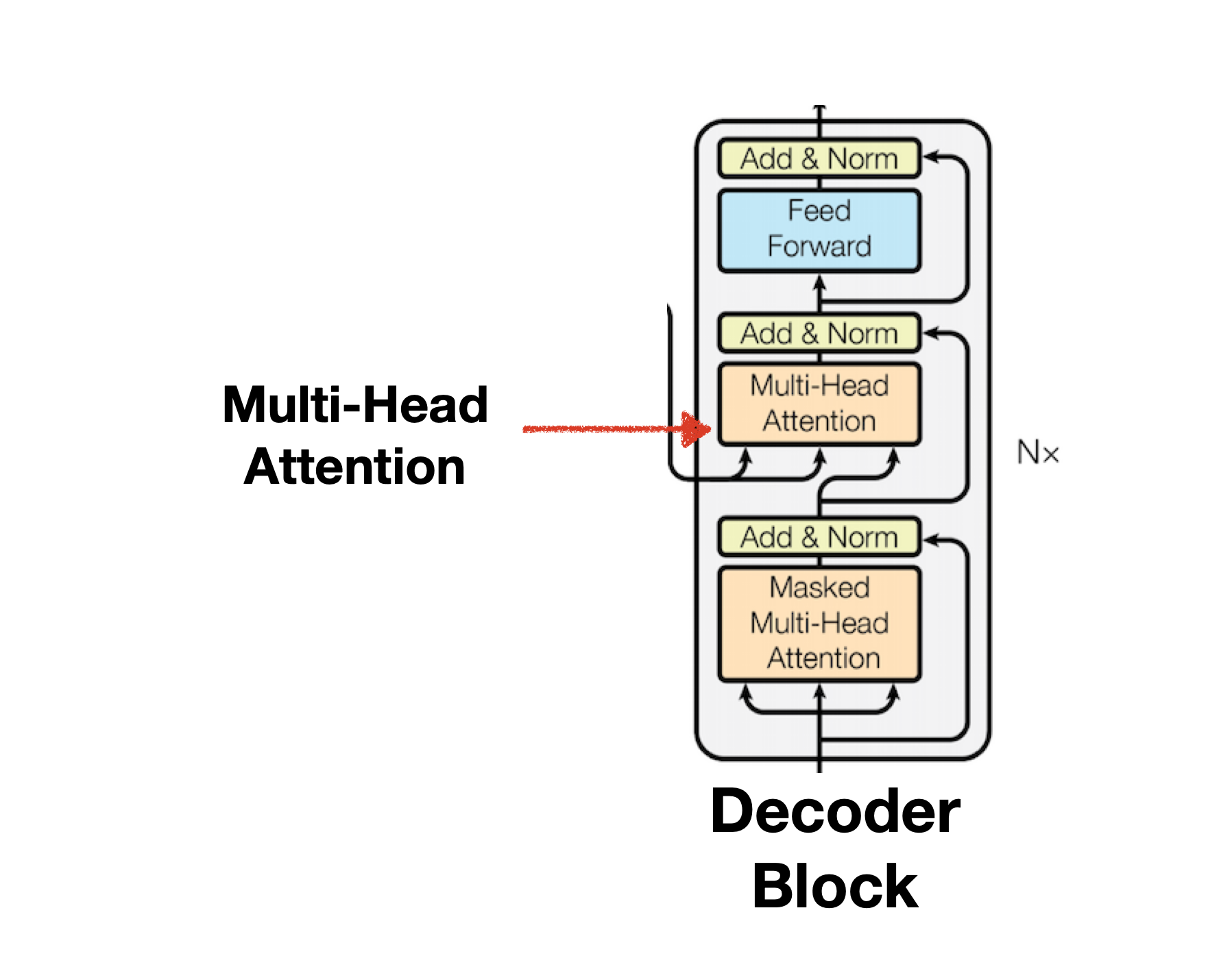
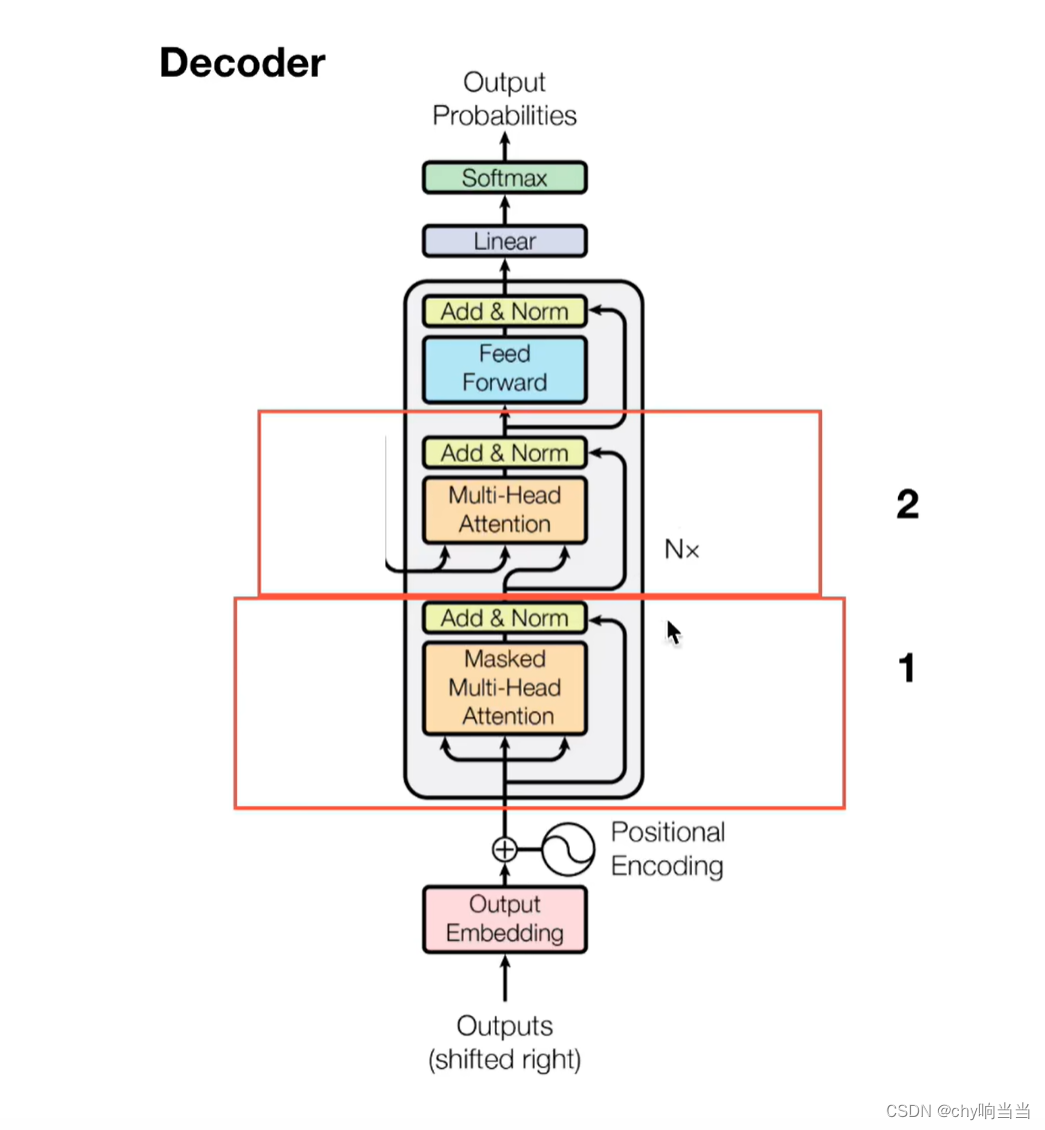
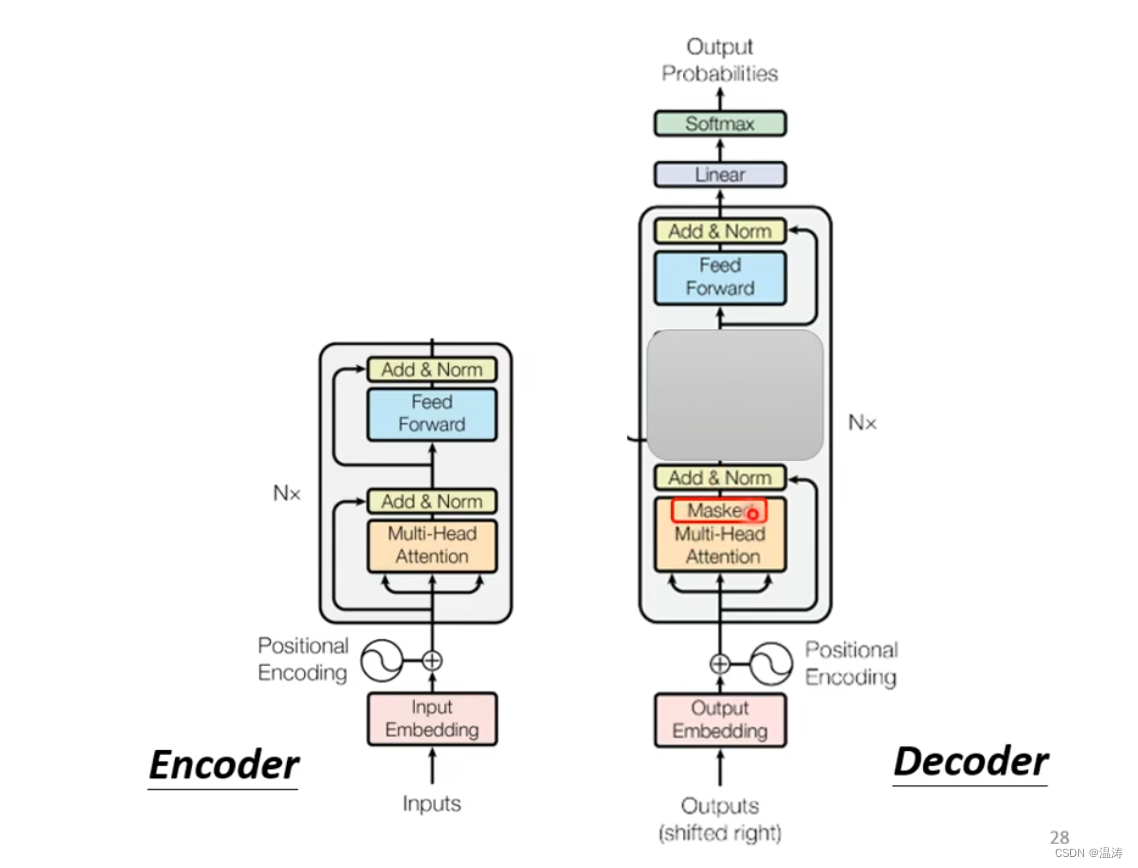
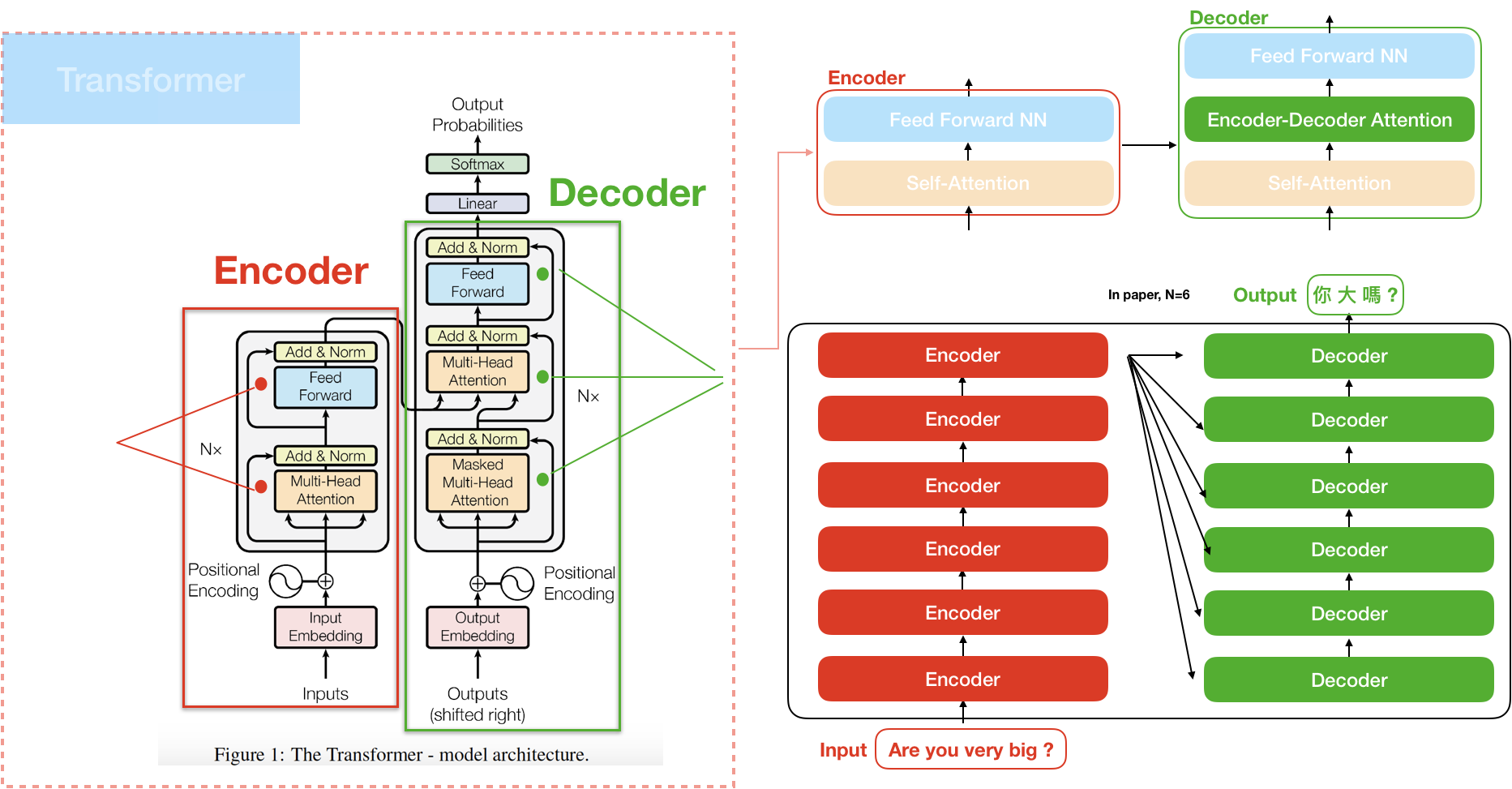
트랜스포머(Transformer) 파헤치기—3. Decoder & Masked Attention
Transformers - Part 7 - Decoder (2): masked self-attention - YouTube
Empirical success distribution for the masked decoder | Download ...
Transformer Decoder | Masked Multi Head Attention, Cross Attention ...
Decoder block of GPT-2 with masked self-attention. [7] | Download ...
Transformer 解读之:用一个小故事轻松掌握 Decoder 端的 Masked Attention,为什么要使用 Mask ...
Visualization of the masked decoder of Oder et al. [OSPG18] | Download ...
BPDec: Unveiling the Potential of Masked Language Modeling Decoder in ...
A pet raccoon cracking random ancient codes the masked decoder ...
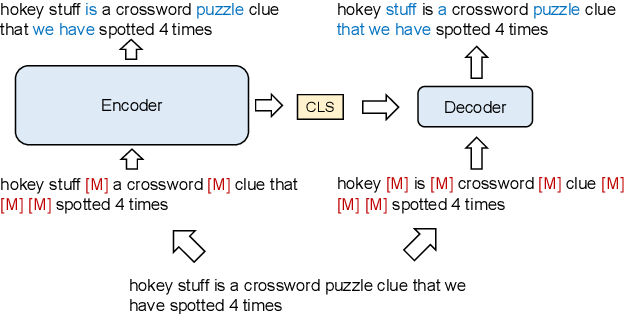
240610_Thuy_Labseminar[Rethinking Tokenizer and Decoder in Masked Graph ...
From Residuals to Masked Attention: The Complete Transformer Decoder ...
Figure 1 from Challenging Decoder helps in Masked Auto-Encoder Pre ...
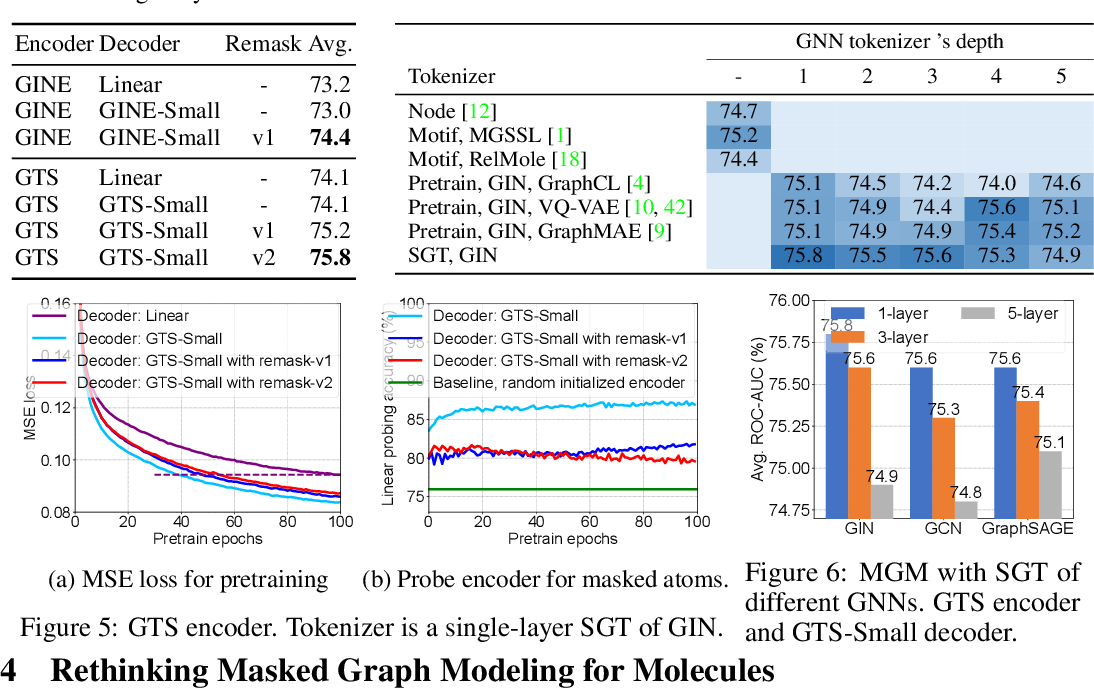
Table 1 from Rethinking Tokenizer and Decoder in Masked Graph Modeling ...
A Deep Dive into Masked Multi-Head Attention in the Decoder | Key to AI ...
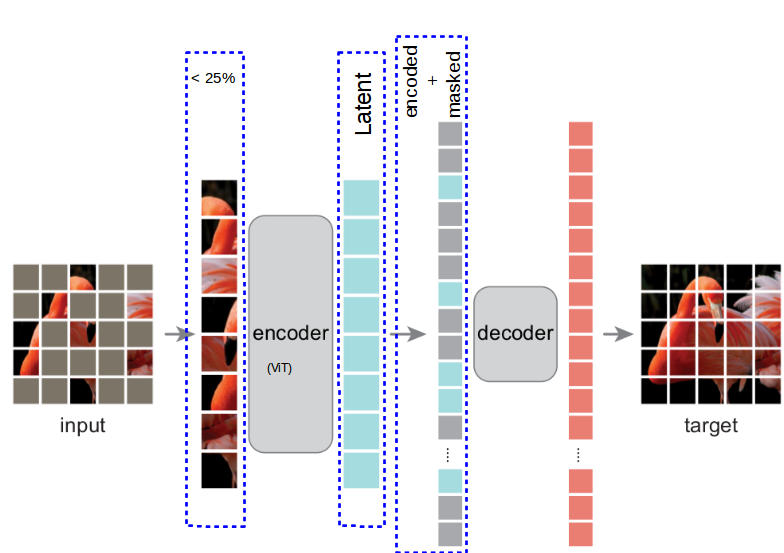
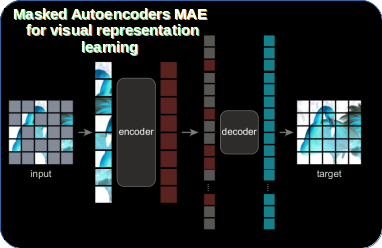
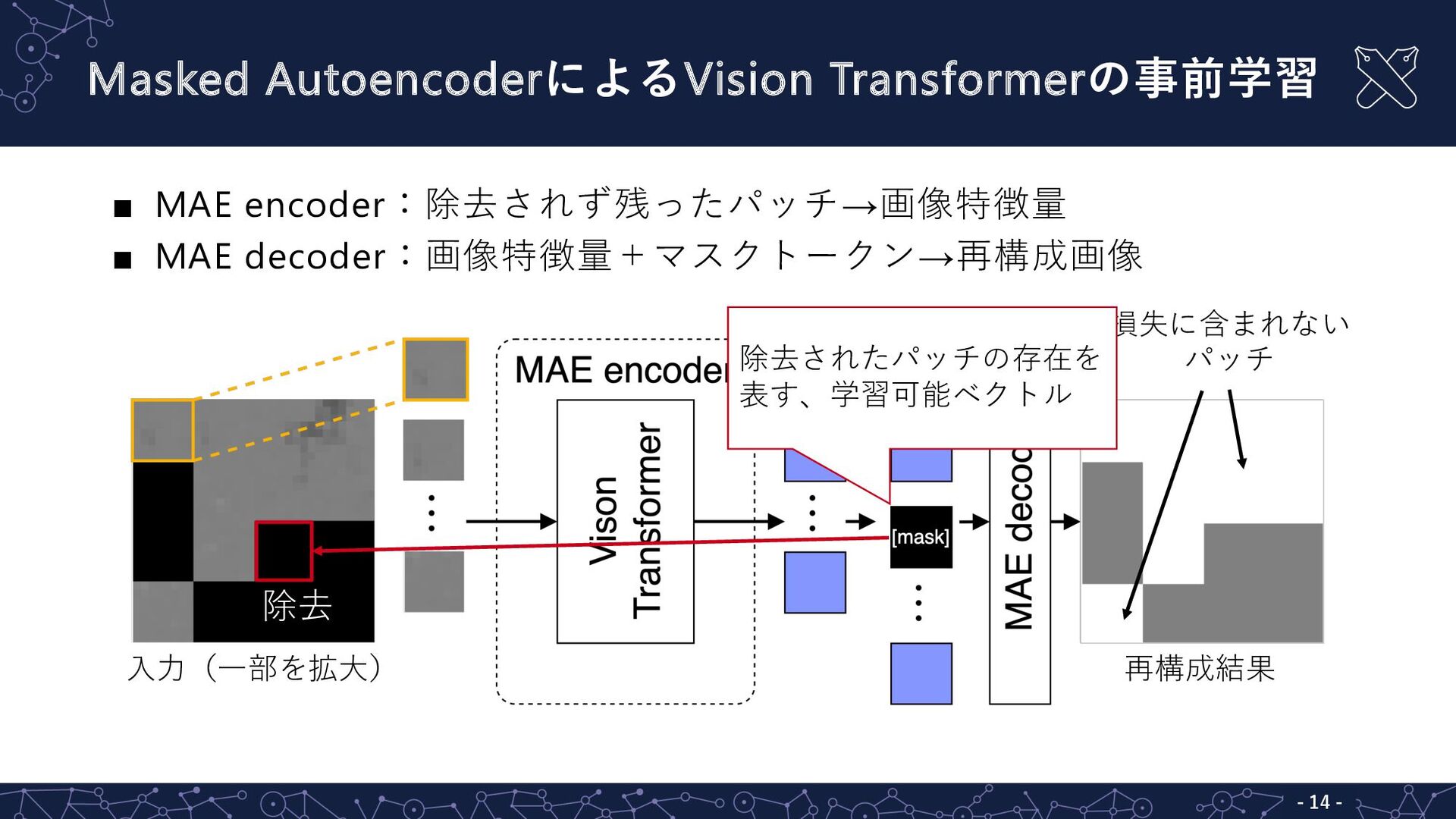
Paper explained: Masked Autoencoders Are Scalable Vision Learners ...
Masked autoencoder (MAE) for visual representation learning. Form the ...
Multi-View Masked Autoencoder for General Image Representation
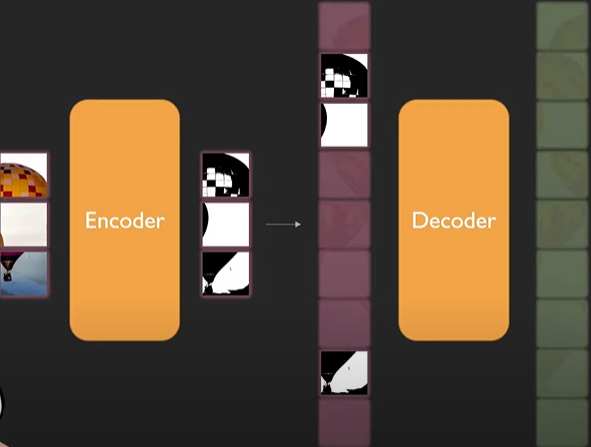
The asymmetric encoder-decoder structure of MAE. The image is masked ...
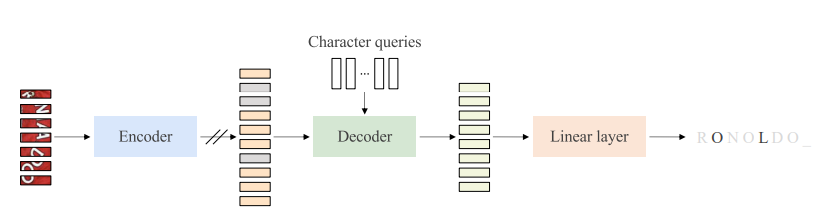
MaskOCR: Text Recognition with Masked Encoder-Decoder Pretraining
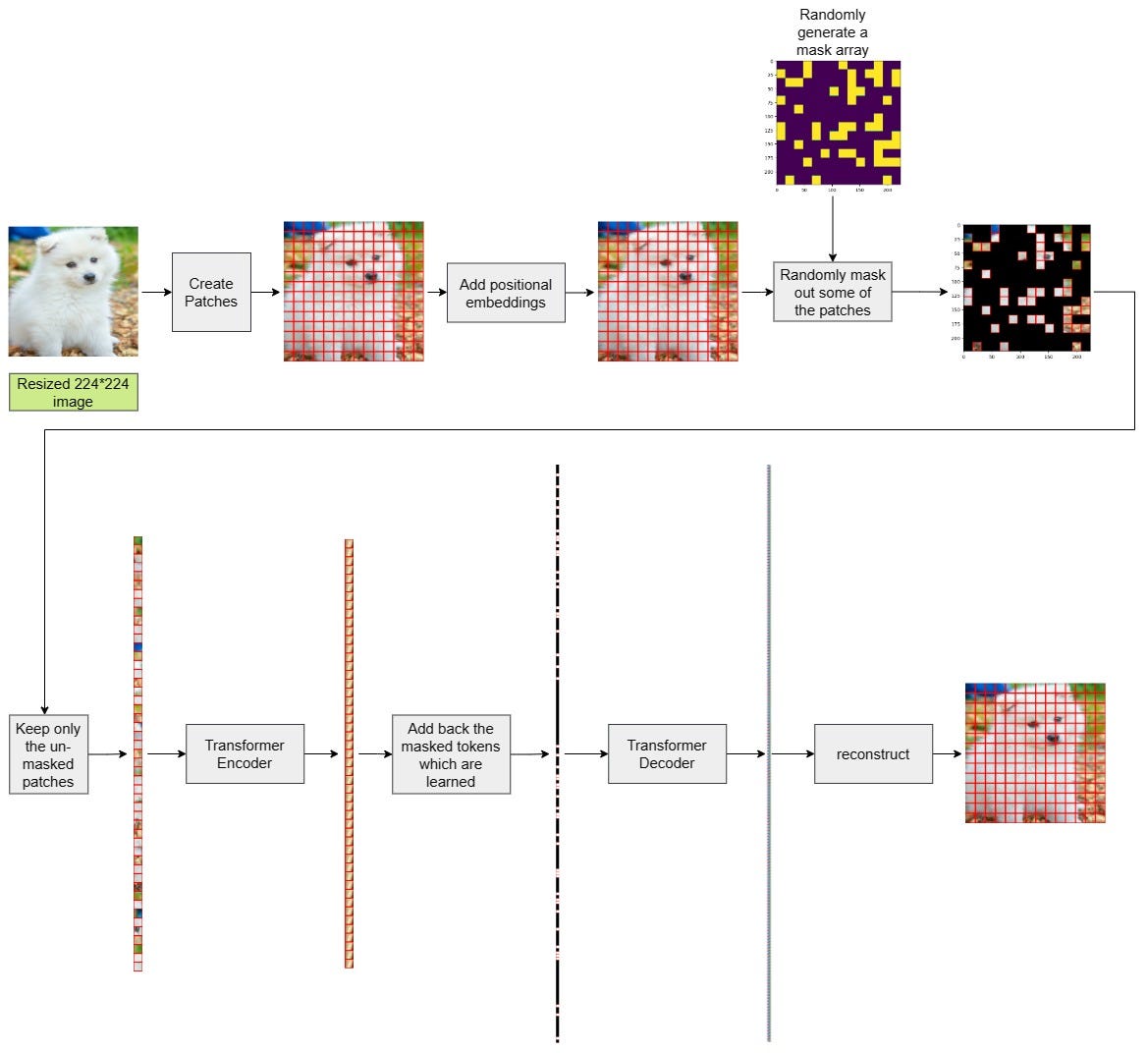
Overview of the masked auto encoder which takes masked images as input ...
[2206.00311] MaskOCR: Text Recognition with Masked Encoder-Decoder ...
Cross-Attention: Connecting Encoder and Decoder in Transformers ...
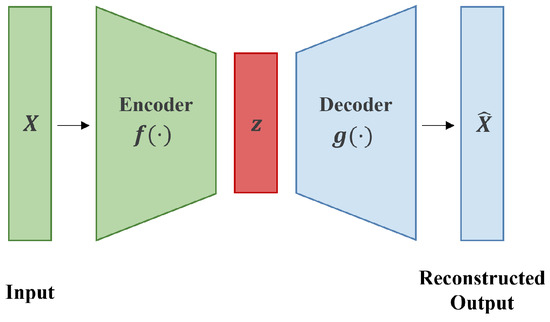
What Are Masked Autoencoders and How Do They Work? | Analytics India ...
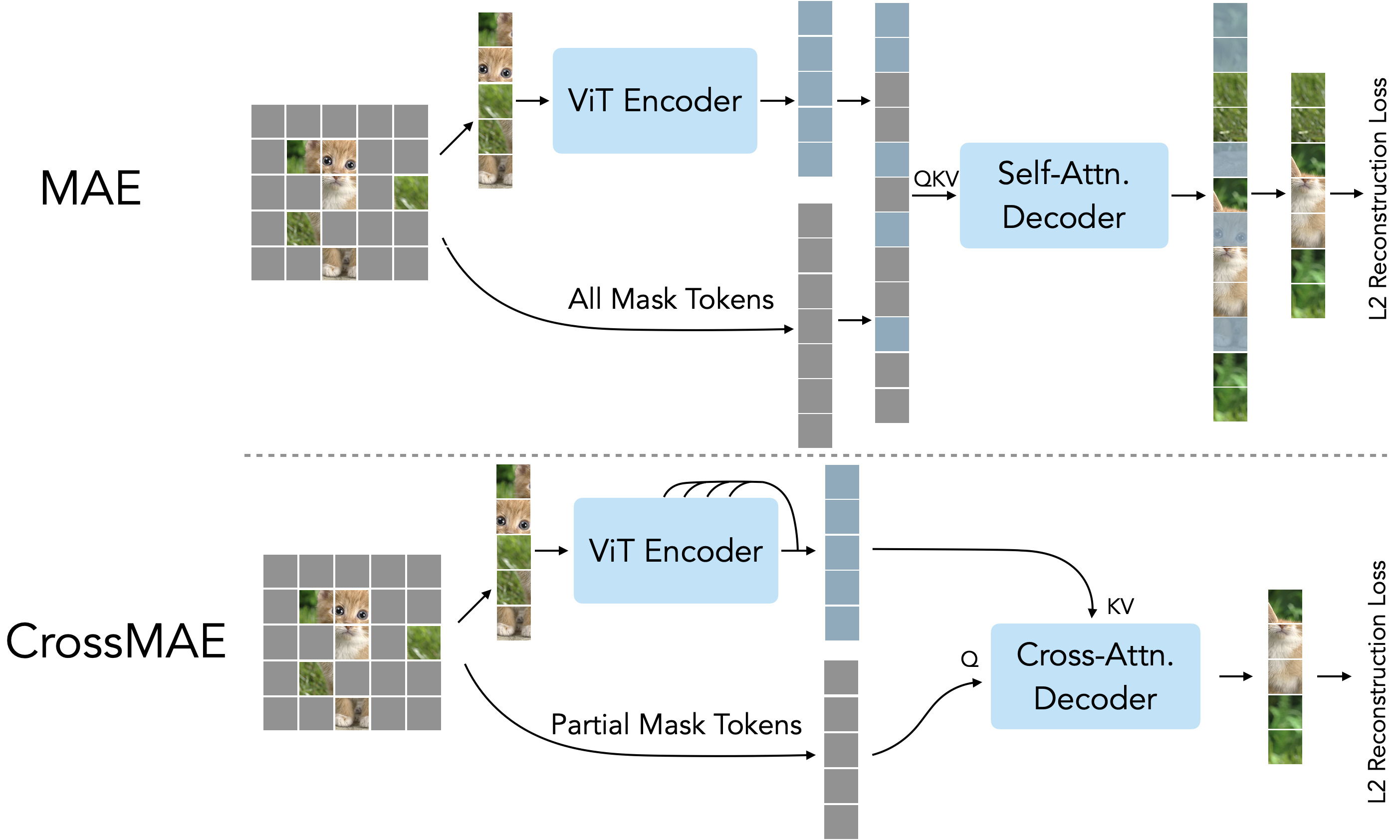
CrossMAE: Rethinking Patch Dependence for Masked Autoencoders
Masked Autoencoders Are Scalable Vision Learners | by Souvik Mandal ...
Multimodal masked autoencoder (M3AE) consists of an encoder that maps ...
Understanding Encoder And Decoder LLMs
PR-355: Masked Autoencoders Are Scalable Vision Learners | PDF
Masked Autoencoders Are Scalable Vision Learners.pptx
简读Diffusion Models as Masked Autoencoders - 知乎
Decoder vs Encoder in Transformer Models | AI Tutorial | Next Electronics
Transformer : encoder 및 decoder (Masked Self-attention)
| Assignment on Masked Autoencoders (MAE) | | PPTX
Decoder-only transformers are just the decoder portion of the ...
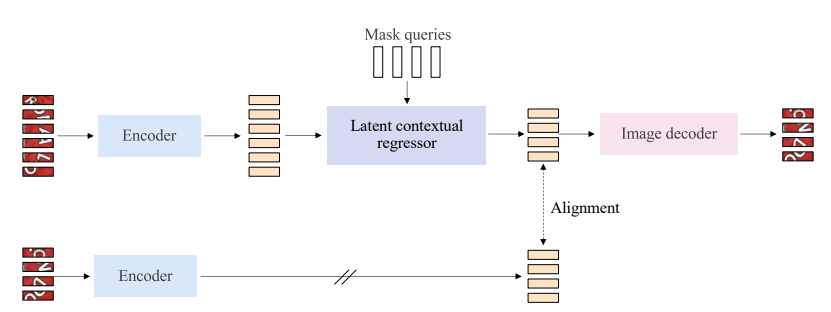
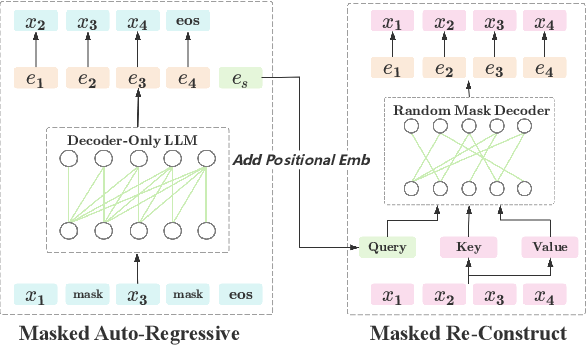
Figure 1 from Decoder-Only LLMs can be Masked Auto-Encoders | Semantic ...
Illustration of the proposed MLP decoder. The lightweight MLP decoder ...
Masked Self Attention | Masked Multi-head Attention in Transformer ...
MAE: Masked Autoencoders are scalable vision learners - 知乎
GitHub - basiclab/CMED: Entity disambiguation using conditional masked ...
Comparison with existing paradigms of masked image modeling. (a ...
Premium Photo | A pet raccoon cracking random ancient codes the masked ...
Mask decoder finetuning · Issue #49 · ChaoningZhang/MobileSAM · GitHub
Figure 1 from MaskOCR: Text Recognition with Masked Encoder-Decoder ...
Attack statistics for the fully masked concatenated decoder. | Download ...
Inside Masked Language Models: Dissecting LLM Pipeline 🚀 | by Jagadesh ...
Decoder-Only LLMs can be Masked Auto-Encoders - ACL Anthology
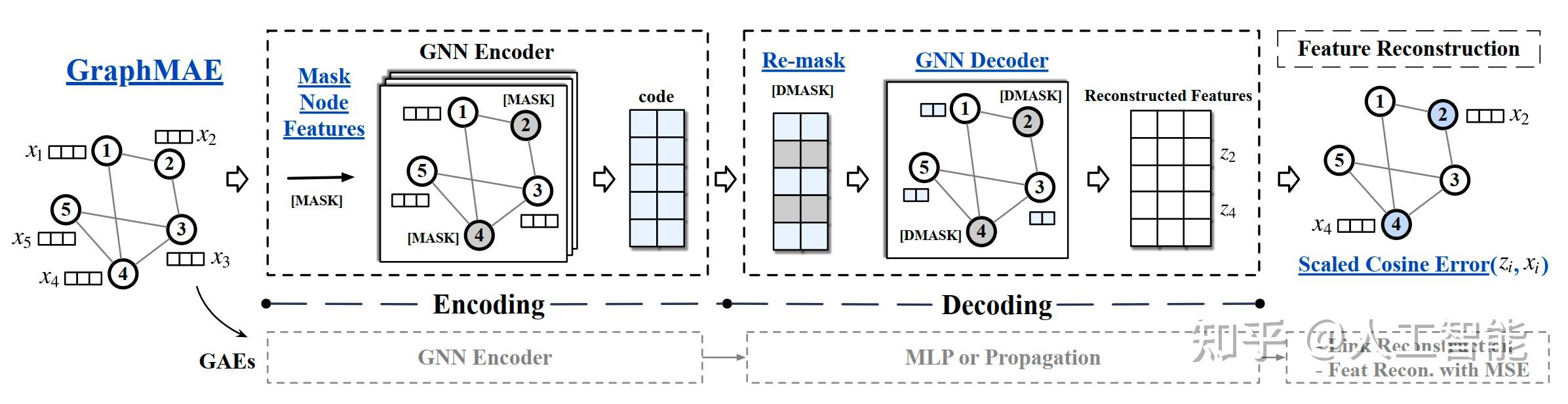
【GNN精读】GraphMAE: Self-Supervised Masked Graph Autoencoders - 知乎
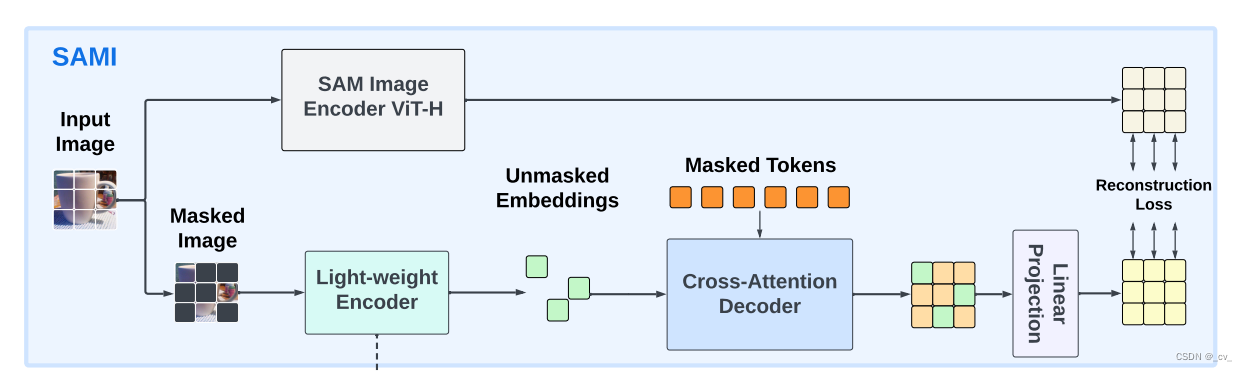
EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment ...
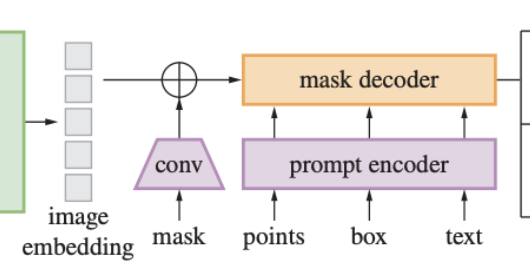
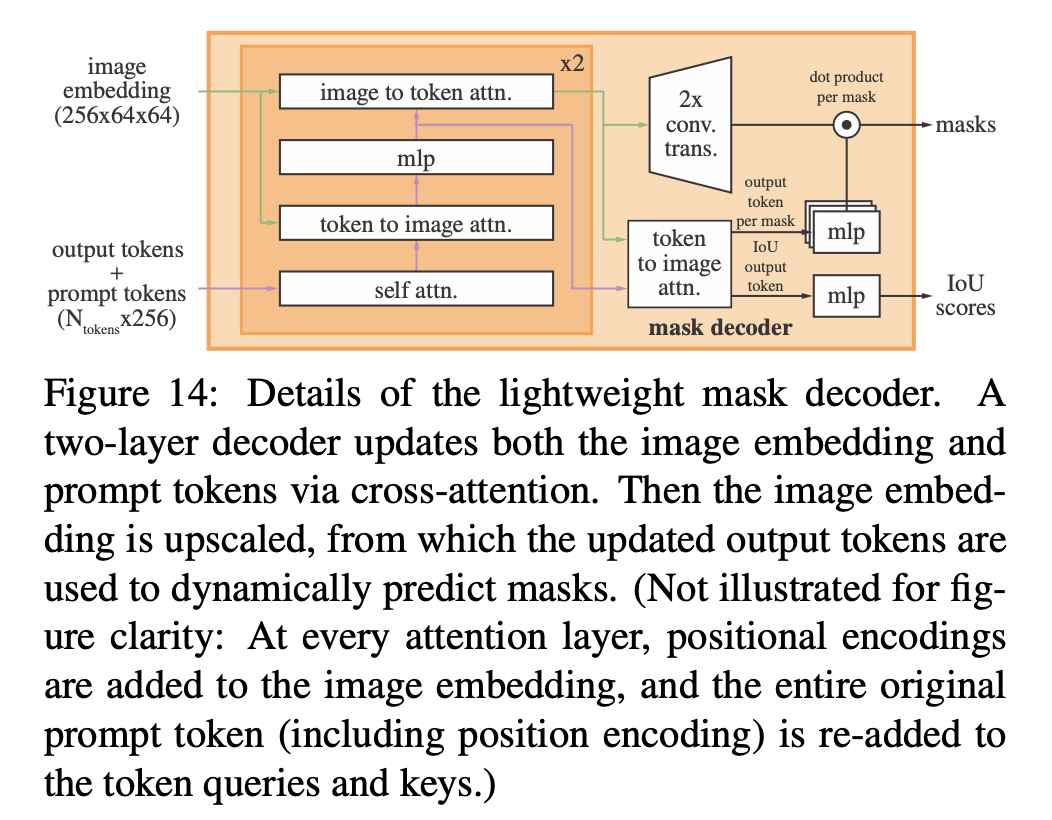
SAM
【图像分割】【深度学习】SAM官方Pytorch代码-Mask decoder模块MaskDeco网络解析
sam模型中的mask decoder_sam mask decoder-CSDN博客
SegmentAnything | Less is More
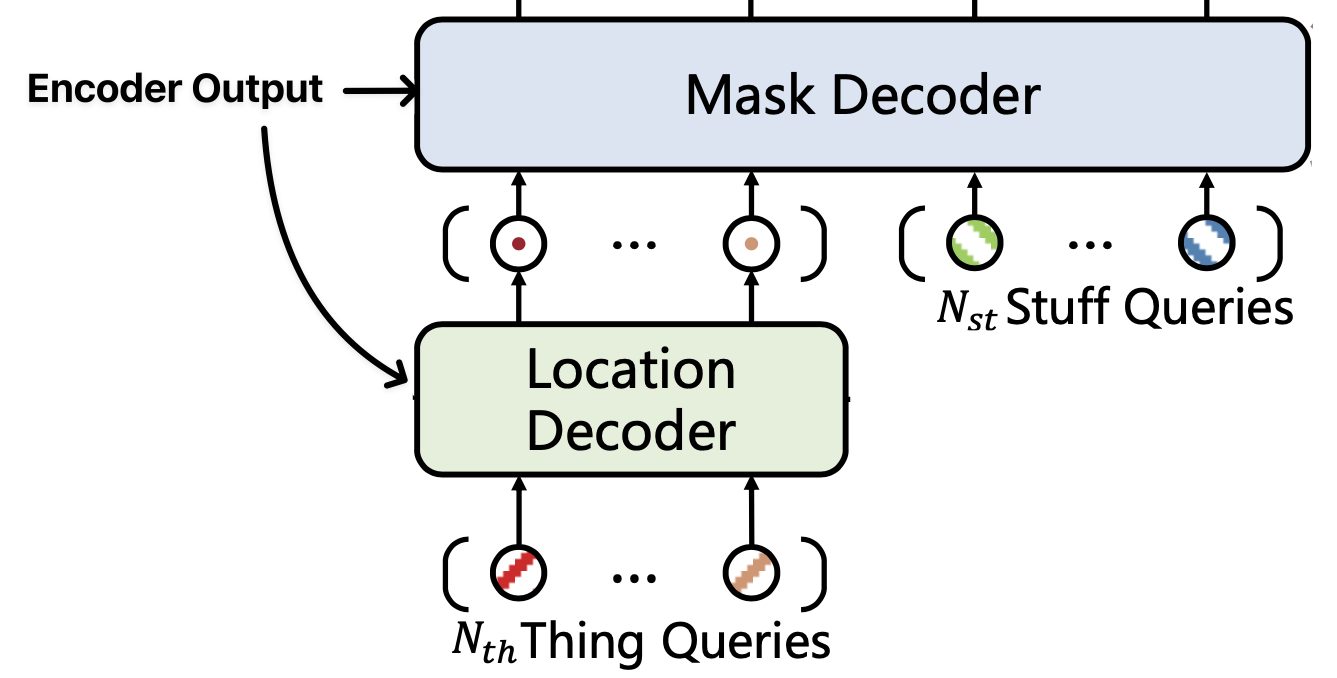
Panoptic SegFormer
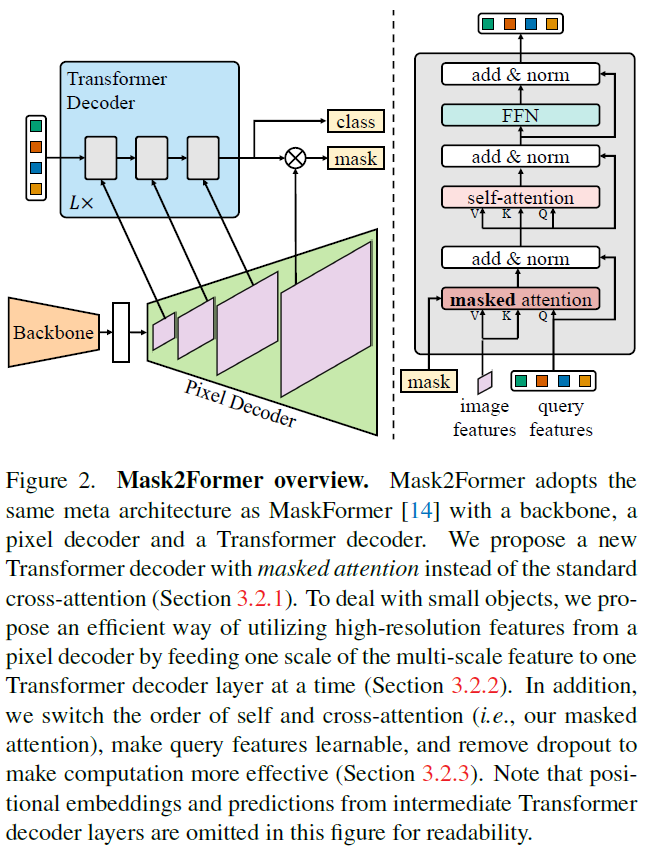
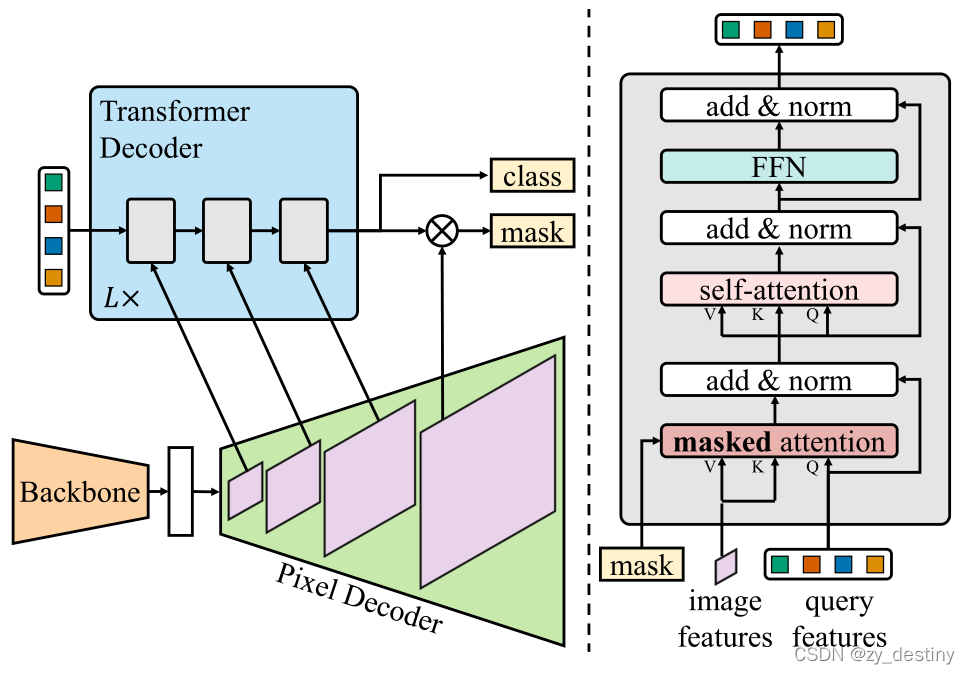
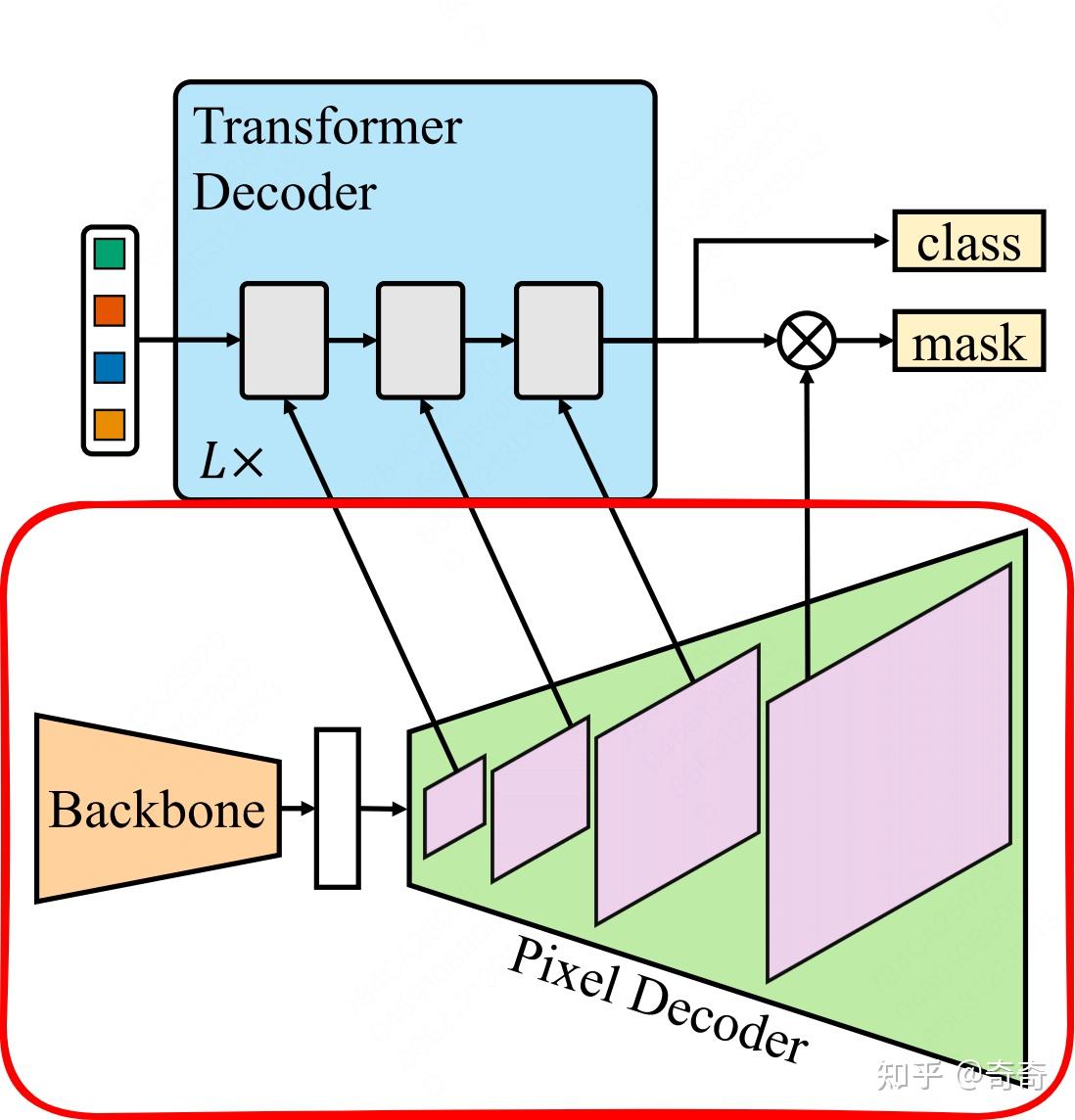
MaskFormer, Mask2Former
【Mask2Former】Masked-attention Mask Transformer for Universal Image ...
Figure 1 from Enhancing Textual Representation for Abstractive ...
【论文阅读】Masked Autoencoders Are Scalable Vision Learners(MAE)-CSDN博客
Masking in Transformer Encoder/Decoder Models - Sanjaya’s Blog
深度学习进阶之Transformer - AI备忘录
Mask2former-Pixel Decoder的输入与输出 - 知乎
Transformer模型详解:编码器、解码器与注意力机制-CSDN博客
从EncoderDecoder到Transformer
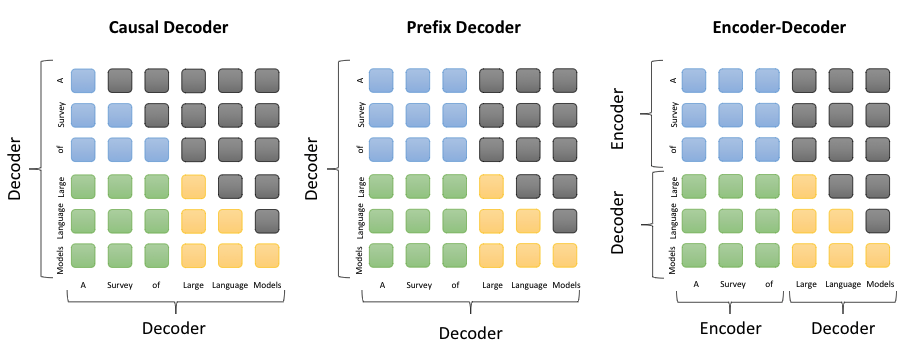
比较Causal decoder、Prefix decoder和encoder-decoder-CSDN博客
Segment Anything 2: What Is the Secret Sauce? (A Deep Learner's Guide ...
Yangoos Github Blog
Figure 2 from Enhancing Textual Representation for Abstractive ...
Transformer 源码中 Mask 机制的实现 - 虾野百鹤 - 博客园
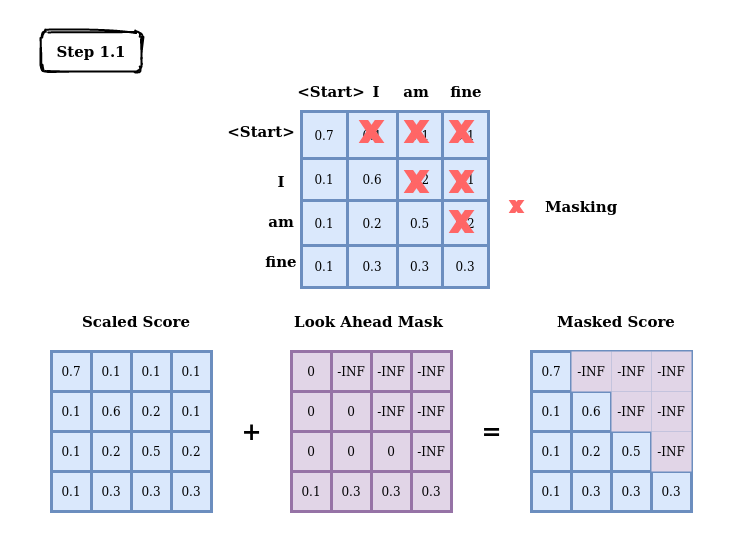
Transformer笔记01_transformer中decoder的注意力模块为什么采用遮蔽操作(masked)?请用文字简单-CSDN博客
Multi head attention mechanism. In the encoder and decoder, multiple ...
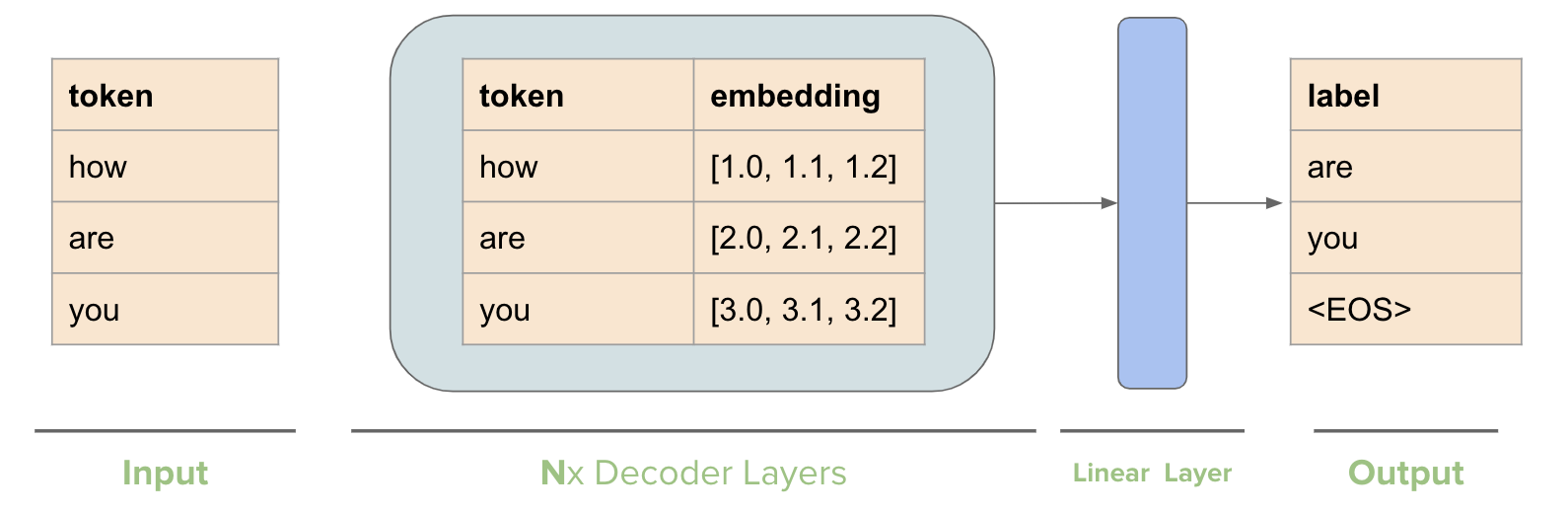
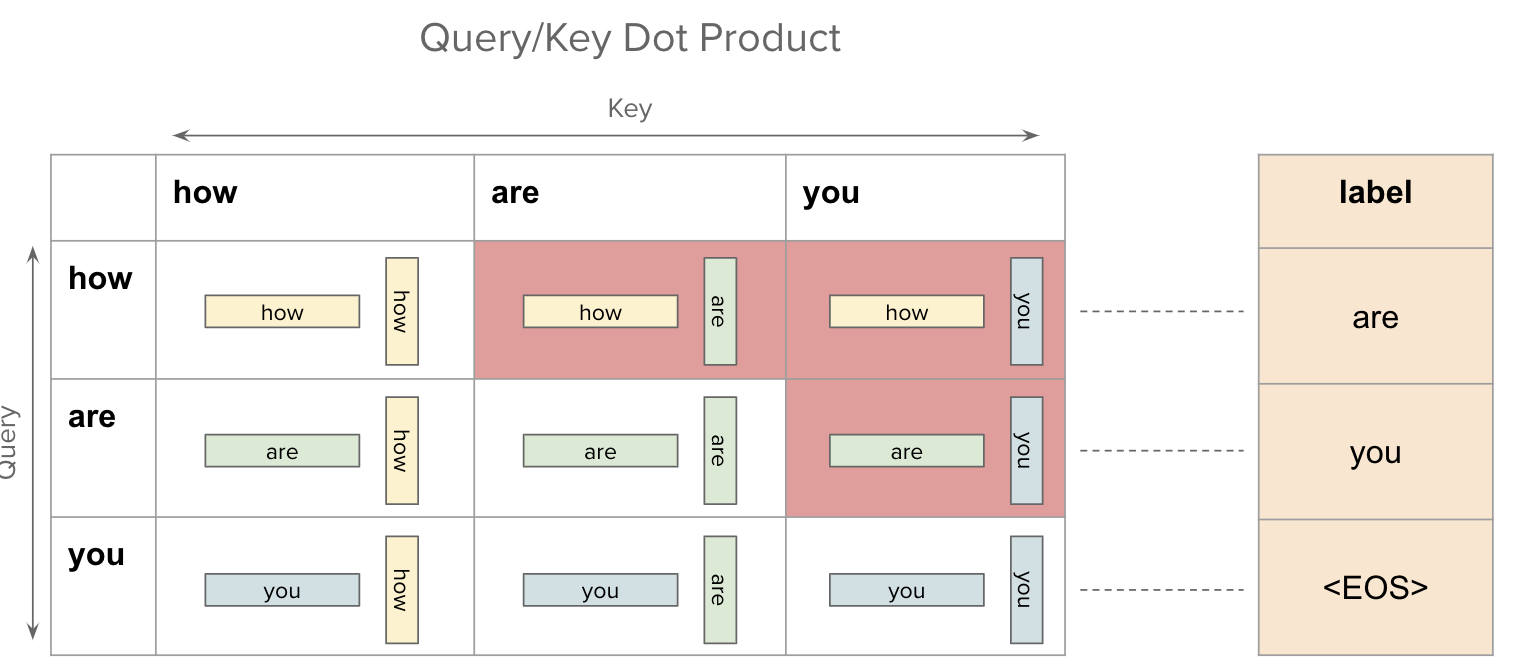
Transformers — Visual Guide
Visualization of the effect of skipping the first subtraction in the ...
Explain the Transformer Architecture (with Examples and Videos) - AIML.com
MaskedDecode q . The final result is a Boolean masking where the most ...
Lecture - 10 Transformer Model, Motivation to Transformers, Principles ...
Transformer【第五章】_transformer的autoregressive decoder-CSDN博客
深入理解Transformer中的解码器原理(Decoder)与掩码机制 - 技术栈
Visually Walking Through a Transformer Model
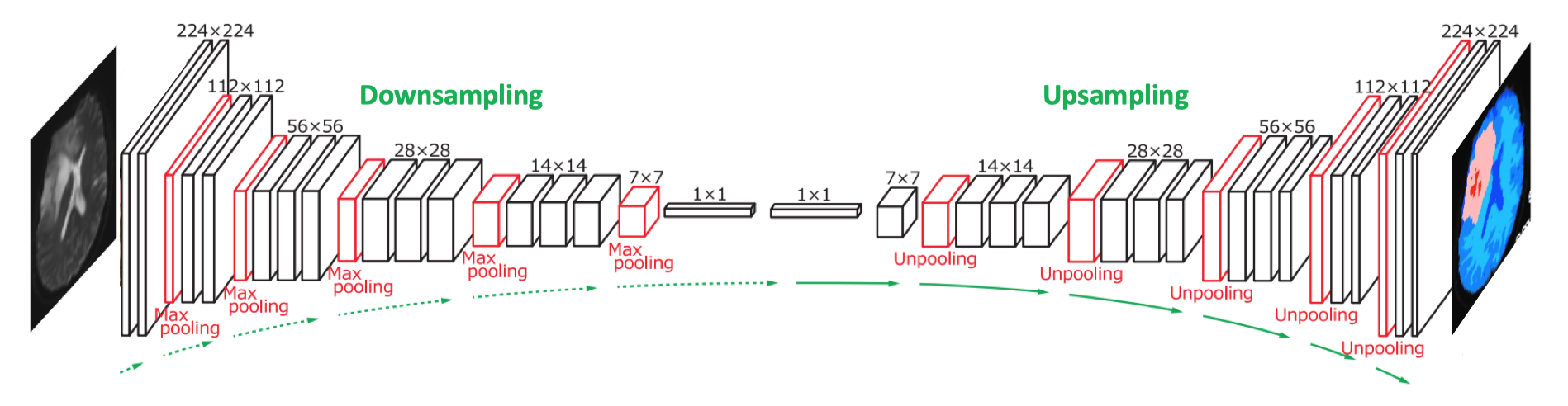
Upsampling - Questions and Answers in MRI
[AIB 18기] Section 3 - Sprint 2 - Note 4 - Transformer
[FIT22]Flare Transformer Regressor: Solar Flare Prediction Based on ...
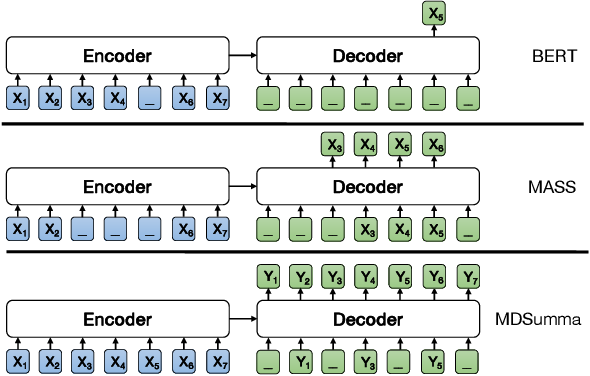
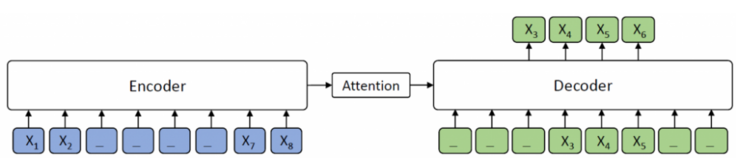
MASS-Masked Sequence to Sequence Pre-training for Language Generation ...
[DL 기본] Transformer
Transformer decoder中masked attention的理解-CSDN博客
Week 7 Presentation Ngoc Ta Aidean Sharghi - ppt download
Kamen Rider: Decode [REDUX] by Masked-Accel on DeviantArt
Transformer - murtaza
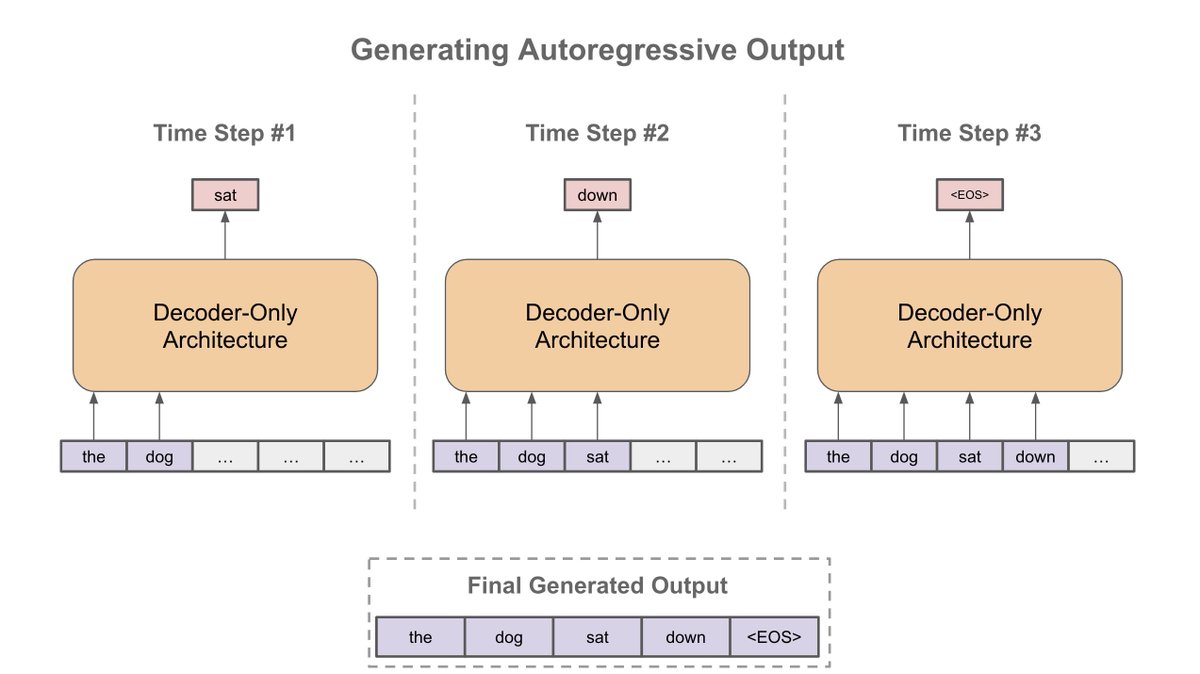
Decoder-Only Transformers: The Workhorse of Generative LLMs
Transformer (Attention Is All You Need) 구현하기 (2/3) | Reinforce NLP
Famous Models — Documentation image segmentation prompt
Mastering the Decoder-Only Transformer: Key Insights
#wondered #languagemodels #decoder #research #models #decoder #encoder ...
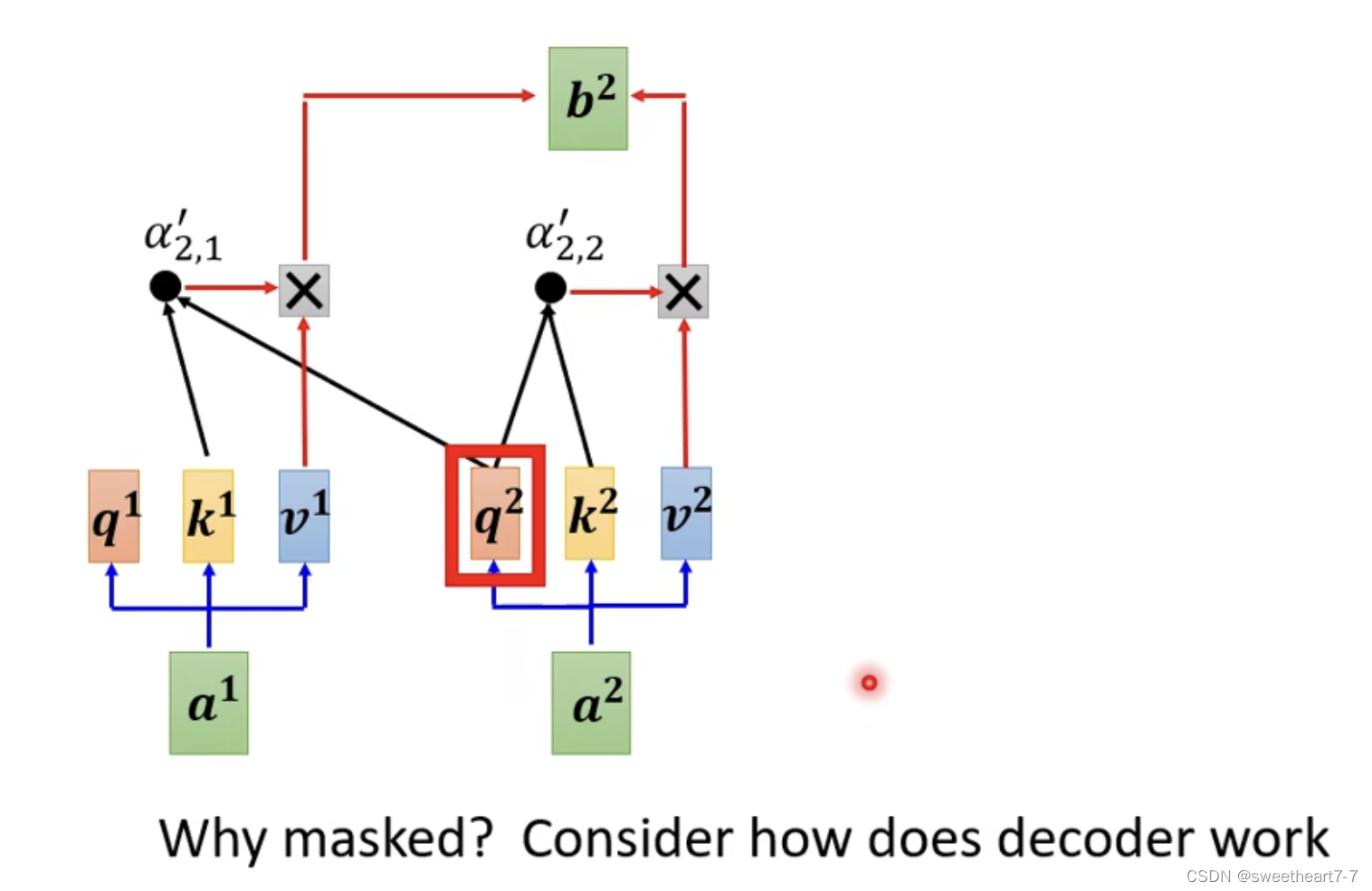
P11机器学习--李宏毅笔记(Transformer Decoder)Testing部分_transformer decoder的输入 ...
一文搞懂Transformer-decoder_transformer decoder-CSDN博客
Transformer(self attention pytorch)代码 - 阿夏z - 博客园
大模型开发 - 一文搞懂Encoder-Decoder工作原理_encoder-decoder模型架构-CSDN博客
Full article: MapSAM: adapting segment anything model for automated ...